Discover the #1 Eggplant Hydroflask -Keep Your Beverage Cold
When it comes to the Eggplant Hydroflask, there’s no denying that this is one water bottle everyone can get…

When it comes to the Eggplant Hydroflask, there’s no denying that this is one water bottle everyone can get…

When planting apple trees, space them 15-20 feet apart to ensure proper growth and yield. This distance allows ample…

If you’re looking for a delicious and easy alternative to pizza sauce, look no further than pasta sauce! Not…

To port a number to Google Voice, you need to go to the Google Voice settings and select the…

To make an absolute reference in Excel on Mac, use the shortcut “Command + T.” Credit: www.wps.com Understanding Absolute…

To boot from USB on Dell laptops, modify the BIOS settings and select the USB storage device as the…

A chair typically weighs between 4 and 8 pounds. How much does a chair weigh? This is a question…
In Cookie Run Kingdom, there are various ways to upgrade Cookie Castle. One way is to use the in-game…
If you need to adjust the carbonation on your soda machine, there are a few things you can do….
The Hario Coffee Scale V60 Digital Scale is a must-have tool for any coffee lover. It is extremely accurate,…

Yes, Govee LED lights support Apple HomeKit and can be easily connected and controlled through voice commands. With support…
Bethesda’s Creation Club is a great way to get new content for your game, but sometimes you may want…
Halo Infinite is one of the most anticipated games of 2020. The game was originally supposed to launch in…

You can grind coffee in a food processor, but it may not produce the desired results. The blades of…

There are many things you can serve with chicken tortilla soup, but some of the most popular include: -Tortilla…
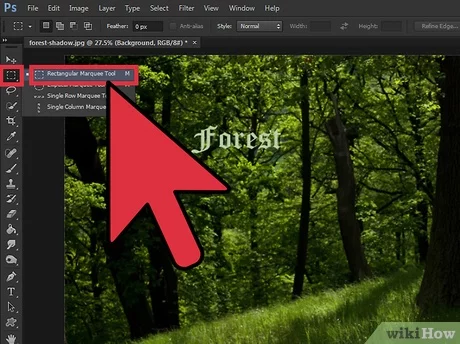
To center text in Photoshop, choose Object > Text Frame Options and select the desired alignment option in the…

Introduction: Pudding is a popular food all over the world, and it’s hard to know how long it will…

“Capture Your Sound – Record Guitar in FL Studio with Ease!” Introduction Recording guitar in FL Studio is a…

To unlock a Samsung A03S phone if you have forgotten the password, you can follow these steps: reset the…
There are a few things you need to do in order to blackout your windows with paint. First, you…

Apple cider vinegar can replace shampoo as an excellent clarifying treatment to remove buildup and soothe the scalp. It…