Discover the #1 Eggplant Hydroflask -Keep Your Beverage Cold
When it comes to the Eggplant Hydroflask, there’s no denying that this is one water bottle everyone can get…

When it comes to the Eggplant Hydroflask, there’s no denying that this is one water bottle everyone can get…
You might be wondering if you can use a carpet cleaner on your mattress and the answer is yes!…
To adjust slack adjusters, release the locking sleeve over the nut and turn the adjusting nut until it goes…
There are a few things you can do to stop your bed from sliding on a wood floor. One…

A shower niche shelf provides a convenient and stylish storage solution for your bathroom essentials. This compact and durable…

To remove reflections in Photoshop, start by saving the selection and loading it, then merge the layers and feather…
The Jeep Wrangler 4xe is a plug-in hybrid SUV that offers both electric and gas power. To charge the…

Step 1: Begin by drawing a circle for the Monopoly man’s head. Add a small rectangle at the bottom…

Track your water intake on Apple Watch with the WaterMinder app. Log drinks directly from your wrist, receive hydration…
There are a few different ways to tab out on Mac, depending on what you need to do. The…

In Excel, you can create graph paper by changing to “Page Layout” view, selecting all cells, formatting the column…

One pound is equal to 0.45359237 kilograms. Therefore, 50 pounds is equal to 22.6796185 kilograms. HOW I Added 50…
There are countless benefits to incorporating fruit into your diet, including improved heart health, weight loss, and increased energy…
It takes varying times to graduate from the Excel Center depending on individual credit and grade entry. The graduation…
Welcome, aspiring chefs and culinary enthusiasts! Today, we embark on a delicious adventure into the world of baking a…
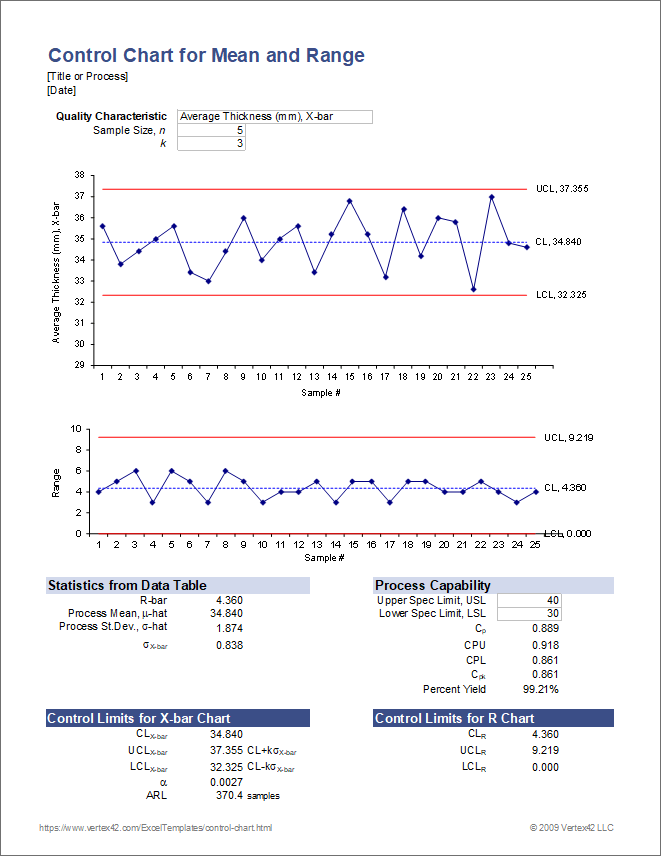
To create a Control Chart in Excel, start by selecting a static data set and setting up control parameters….
Rue McClanahan’s net worth was $40 million at the time of her death. She was an American actress, writer,…
When it comes to gun control, the debate over red flag laws is certainly a hot topic. Red flag…

Corviknight Vmax is a new card from the Sword and Shield set in the Pokémon Trading Card Game. It’s…
If you’re a fan of the popular online game Fortnite, then you’ve probably seen the term “BM” being used…

To determine the size of your Apple Watch, check the model number located in the “About” section of the…